
Introduction
When I started out my career, I didn’t give much thought to databases. To my junior eyes, big security problems were in the webservers, the code, not really in the database.
Now, imagine you’re a young startup. You want to go fishing for clients and hire a few developers. They grab a DB engine, sprinkle code on top, and voilà, you’ve landed a customer. They’ve put the DB in a private subnet, so it’s secure too!
A few years down the line, you’ve become a stable business with a large enough team to maintain your service. That same DB you created all that time ago, is still here. Its root password is still 8 characters long, and all your fancy containers have it hardcoded in a config file somehwere.
Reality check
While this scenario might seem over the top, your organisation has very probably gone through some version of it. When you’re pressed for time, it’s not easy to do everything perfectly. Anything not directly related to customer facing feature gets put on the backburner, and eventually turns into technical debt.
In the real world, databases are not friendly beasts. Large organisations pay specialised DB admins to tame them. In your startup, safe & secure databases will probably end up as technical debt.
From a security standpoint, databases (and datastores in general) are among the most sensitive assets a SaaS organisation can have. Yet, in my experience, SaaS scale-ups tend to overlook the work necessary to securely operate their DBs for 2 reasons:
- 👉 It doesn’t deliver immediate business value
- 👉 “We’ve enabled auto-updates on AWS to secure it!”
The challenge
My organisation was in a similar situation, but we had decided that we needed to improve. My teammates and I set to work, and as usual, I focussed on introducing new security features.
I started by researching DB security best practices on reputable online sources. Looking at the OWASP’s DB security recommendations and this SANS white paper, we can educe the following categories of security measures applicable to databases:
- 👉 Network segmentation
- 👉 Encryption in transit & at rest
- 👉 RBAC
- 👉 Backups
- 👉 Monitoring & logging
The pain points
Having reviewed our setup, we were satisfied with the network segregation and the implemented backup strategy (AWS really does make it very easy). DB volumes were encrypted at rest, and DB connections went through TLS tunnels, so our bases (encryption-wise) were covered.
The next step would have been enabling column-level encryption or client-side encryption within our database instances, but that was not never going to be a priority until we addressed the main pain points we had 👇.
Root access
DB instances were provisioned on AWS using Terraform, and the root password set with Terraform too.
Root credential rotation was not automated and just like the app’s credentials, it was a manual chore.
Monitoring
The platform team had a Grafana environment already in place, and was looking at pushing it as the only monitoring and alerting service for all internal users. It did not address database metrics yet unfortunately. As a result, engineers in the organisation needed access to our AWS account to check on their DB’s health.
App access
Each microservice had its own database & interacted with it using a set of static credentials. Changing these credentials required a manual operation on the database.
This was a problem for several reasons:
- Compliance requires us to rotate the password on a regular basis, and it was a boring, arduous process ;
- From a security standpoint, an attacker that had managed to steal the DB’s credentials had an extended window of time to steal all the data ;
- Checking who or what accessed the database was not possible.
User access
Debugging is a fact of life, whether we like it or not. At some point, someone might require access to a database, most probably a DB admin or a senior engineer.
We needed a clear workflow to manage these situations.
Automation as a paradigm
What exactly did we want to accomplish here?
| Issue | Target |
|---|---|
| Root password | Rotate passwords easily |
| Monitoring | Automate DB health metrics collection & display |
| App access | Rotate passwords frequently and easily |
| User access | Provide on-demand, monitored, safe RBAC to users |
Automation is the answer to all these issues.

Luckily, our organisation had gone all in on standardisation. All our microservices were built the same way, with the same technologies, and ran on the same infrastructure, described by (nearly) the same IaC. As a result, it was very easy for us to replicate any automated solution we created across all our apps.
Let’s tackle each point individually.
Automation vs. database root access
As previously stated, we used Terraform to create our databases & set their root passwords. More specifically, Terraform would fetch a secret stored in our HashiCorp Vault and configure it in the database resource.
|
|
Some of you in the back are already clamoring “But this means the secret is stored in cleartext in the Terraform state!”. Yes, indeed, and that is a separate security issue, that our team had already adressed.
With this setup, you can’t just change the value stored in the Vault, and reapply the Terraform. If you tried doing that, Terraform would tell you it cannot access the DB, and thus cannot change the password. Consequently, rotating the password is considerably more involved than just reapplying the Terraform stack.
Now, how do we improve this? Ideally we would like to be able to rotate the password with a single Terraform run.
All it takes is a bit of Terraform wizardry: I created a module that generated a random password that depended on a resource that would rotate at the end of its useful life.
|
|
This bit of code allowed us to rotate a DB’s root password with a single run of terraform apply whenever the rotation period expired.
I would suggest adding a reminder to your team’s calendar as well as a doc page explaining the whole process to help smooth your next rotation.
Automation vs. database monitoring
PostgreSQL was the standard database for all our microservices.
The easiest way to send PG DB metrics to Grafana, was to use the community provided Prometheus Postgres exporter. We only needed one instance of the exporter per app database, so running it as a sidecar container was out of the question, since many of our apps had multiple pods. It made sense for us to run it as an individual pod in the same namespace as the app pods. We ended up including it in every app’s Helm chart (in the Deployment to be specific).
The exporter obviously needs access to the database, and we weren’t enthusiastic about giving it the same access our applications had. It was best to give it limited read-only access, to protect ourselves from potential upstream supply chain attacks. Hence, a new monitoring user needed to be deployed on all our database instances. For that, we created a Terraform module based on the PostgreSQL provider for Terraform, making use of the role & grant resources, and storing the monitoring user’s credentials on HashiCorp Vault.
Automation vs. database access
Onto the harder problem we had to tackle. How do you do RBAC on a database, both for code & for humans? If it was a regular webapp with human users, we’d go for SAML SSO, but databases don’t always support SAML; PG natively supports a handful of authentication methods, none of which is SAML. Let’s break down the problem into subproblems.
👉 How does RBAC work inside a Postgre DB?
In the PostgreSQL universe, everything is a role.
While the concepts of users & groups do exist, they can be regarded as roles with specific features. For instance, a PG user is simply a role that is allowed to login.
Permissions are additive in PostgreSQL. To add a permission to a role, you grant that permission (eg. GRANT SELECT ON TABLE table1 TO user1).
By default, a role has no permissions whatsoever on any object in the database, except those that it owns, either because the role created them or inherited the ownership.
Roles can be inherited, simply by running a grant statement, for example GRANT big_role TO small_user.
Here, small_user is given the same permissions as big_role and can interact with objects big_role owns.
small_user can be granted other permissions that won’t be available to big_role.
👉 How do you do RBAC inside the DB in a way that allows both machine & human access?
Knowing all this about permissions inside Postgre DBs, we now have to design a way for the code & our engineers to interact with the same application data.
We could have an app role own all objects inside the DB.
If the human roles inherit that app role, read-only access would not be possible.
So the humans roles would need to be separate from app, and the right permissions granted for each one.
We chose the following architecture for the roles inside the DBs:
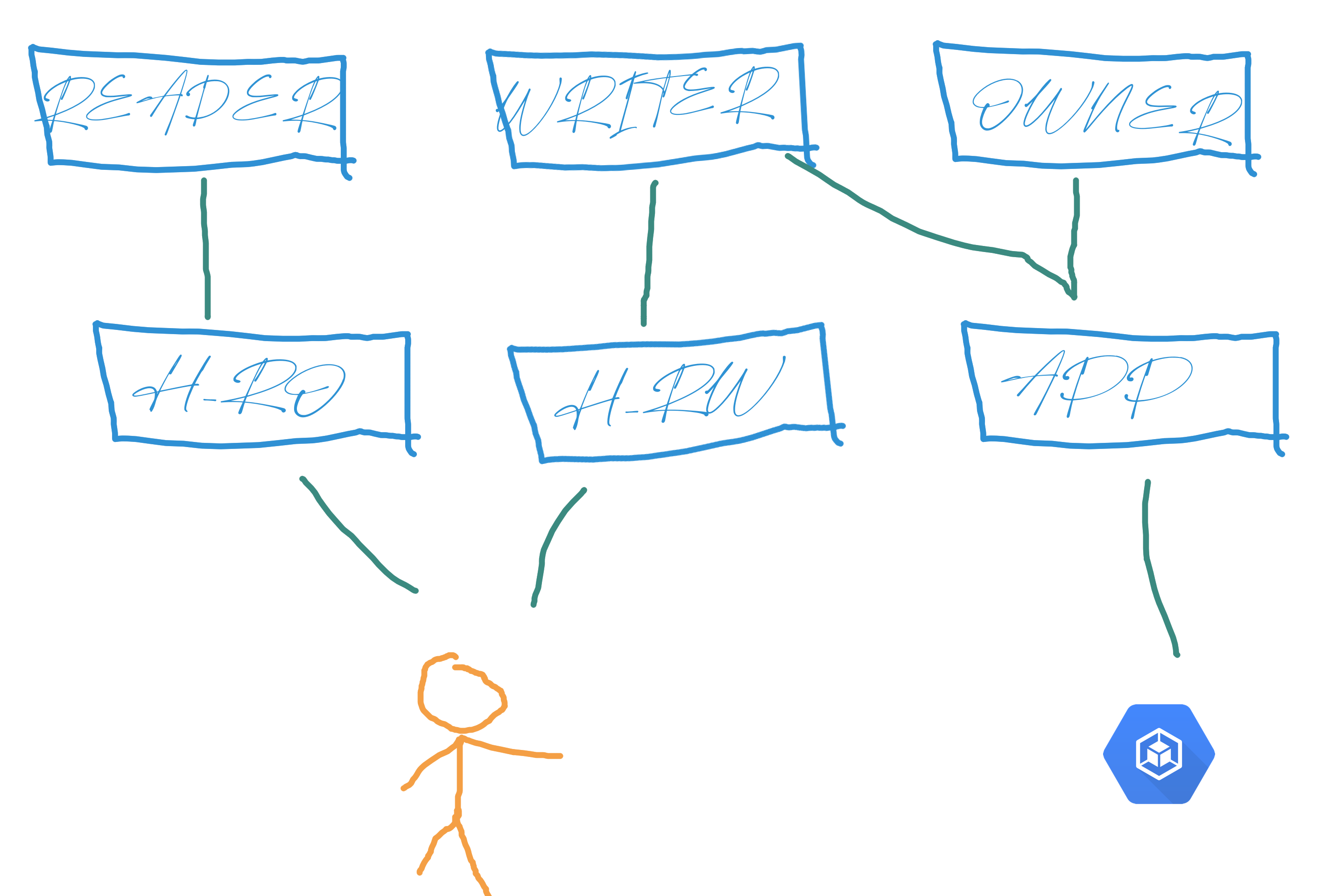
These roles are created once and for all, using Terraform, and granted the right permissions on all existing database objects.
For our apps to function correctly, they need to be able to do their own migrations on the DBs.
That’s why app inherits owner’s permissions. The owner role is given ownership of all objects in the database by running the below 👇 script once.
We chose to not use the REASSIGN OWNED BY command for 3 reasons:
2 engineers in our team had issues with it in the past; stackoverflow had a few examples of it going awry (eg 1, eg 2); and we only had fairly basic resources in our databases.
We preferred running commands we owned & understood.
Ownership transfer script
Run the below script with this command
psql \
-h DB_URL -p 5432 \
-U DB_ADMIN_USER \
-v schema_name="'SCHEMA'" \
-v new_role_name="'NEW_OWNER'" \
-v old_role_name="'OLD_OWNER'" \
-f migration_script.sql
# migration_script.sql
/********************************************
* Create a function to run SQL statements
********************************************/
CREATE OR REPLACE FUNCTION ChangeObjectsOwnerShip(text)
returns text language plpgsql volatile
AS $f$
BEGIN
EXECUTE $1;
RETURN $1;
END;
$f$;
/****************************************************************************************
* Get all FUNCTIONS owned by `old_role_name` and change owner to `new_role_name`
****************************************************************************************/
SELECT ChangeObjectsOwnerShip(
'ALTER FUNCTION ' || quote_ident("Name") || '(' || arg_types || ') OWNER TO ' || quote_ident(:new_role_name))
FROM
(SELECT proowner::regrole,
p.proname AS "Name",
pg_catalog.pg_get_function_arguments(p.oid) AS "arg_types",
CASE p.prokind
WHEN 'a' THEN 'agg'
WHEN 'w' THEN 'window'
WHEN 'p' THEN 'proc'
ELSE 'func'
END AS "Type"
FROM pg_catalog.pg_proc p
LEFT JOIN pg_catalog.pg_namespace n ON n.oid = p.pronamespace
WHERE pg_catalog.pg_function_is_visible(p.oid)
AND n.nspname <> 'pg_catalog'
AND n.nspname <> 'information_schema'
AND n.nspname ~ (:schema_name)
AND proowner::regrole::text ~ quote_ident(:old_role_name)
AND p.proname !~ 'ChangeObjectsOwnerShip' )s;
/****************************************************************************************
* Get all MATERIALIZED VIEWS owned by `old_role_name` and change owner to `new_role_name`
****************************************************************************************/
SELECT ChangeObjectsOwnerShip(
'ALTER MATERIALIZED VIEW ' || quote_ident("Name") || ' OWNER TO ' || quote_ident(:new_role_name))
FROM
(SELECT n.nspname AS "Schema",
c.relname AS "Name",
CASE c.relkind
WHEN 'r' THEN 'table'
WHEN 'v' THEN 'view'
WHEN 'm' THEN 'materialized view'
WHEN 'i' THEN 'index'
WHEN 'S' THEN 'sequence'
WHEN 's' THEN 'special'
WHEN 'f' THEN 'foreign table'
WHEN 'p' THEN 'partitioned table'
WHEN 'I' THEN 'partitioned index'
END AS "Type",
pg_catalog.pg_get_userbyid(c.relowner) AS "Owner"
FROM pg_catalog.pg_class c
LEFT JOIN pg_catalog.pg_namespace n ON n.oid = c.relnamespace
WHERE c.relkind IN ('m','')
AND n.nspname <> 'pg_catalog'
AND n.nspname <> 'information_schema'
AND n.nspname ~ (:schema_name)
AND n.nspname !~ '^pg_toast'
AND pg_catalog.pg_table_is_visible(c.oid)
AND pg_catalog.pg_get_userbyid(c.relowner) ~ quote_ident(:old_role_name))s;
/****************************************************************************************
* Get all TABLE owned by `old_role_name` and change owner to `new_role_name`
****************************************************************************************/
SELECT ChangeObjectsOwnerShip(
'ALTER TABLE ' || quote_ident("Name") || ' OWNER TO ' || quote_ident(:new_role_name))
FROM
(SELECT n.nspname AS "Schema",
c.relname AS "Name",
CASE c.relkind
WHEN 'r' THEN 'table'
WHEN 'v' THEN 'view'
WHEN 'm' THEN 'materialized view'
WHEN 'i' THEN 'index'
WHEN 'S' THEN 'sequence'
WHEN 's' THEN 'special'
WHEN 'f' THEN 'foreign table'
WHEN 'p' THEN 'partitioned table'
WHEN 'I' THEN 'partitioned index'
END AS "Type",
pg_catalog.pg_get_userbyid(c.relowner) AS "Owner"
FROM pg_catalog.pg_class c
LEFT JOIN pg_catalog.pg_namespace n ON n.oid = c.relnamespace
WHERE c.relkind IN ('r','p','')
AND n.nspname <> 'pg_catalog'
AND n.nspname <> 'information_schema'
AND n.nspname ~ (:schema_name)
AND n.nspname !~ '^pg_toast'
AND pg_catalog.pg_table_is_visible(c.oid)
AND pg_catalog.pg_get_userbyid(c.relowner) ~ quote_ident(:old_role_name))s;
/****************************************************************************************
* Get all TEXT SEARCH CONFIGURATION owned by `old_role_name` and change owner to `new_role_name`
****************************************************************************************/
SELECT ChangeObjectsOwnerShip(
'ALTER TEXT SEARCH CONFIGURATION ' || quote_ident("Name") || ' OWNER TO ' || quote_ident(:new_role_name))
FROM
(SELECT c.cfgowner::regrole,
n.nspname AS "Schema",
c.cfgname AS "Name",
pg_catalog.obj_description(c.oid, 'pg_ts_config') AS "Description"
FROM pg_catalog.pg_ts_config c
LEFT JOIN pg_catalog.pg_namespace n ON n.oid = c.cfgnamespace
WHERE pg_catalog.pg_ts_config_is_visible(c.oid)
AND n.nspname ~ (:schema_name)
AND c.cfgowner::regrole::text ~ quote_ident(:old_role_name))s;
/****************************************************************************************
* Get all TYPE owned by `old_role_name` and change owner to `new_role_name`
****************************************************************************************/
SELECT ChangeObjectsOwnerShip(
'ALTER TYPE ' || quote_ident("Name") || ' OWNER TO ' || quote_ident(:new_role_name))
FROM
(SELECT t.typowner::regrole,
n.nspname AS "Schema",
pg_catalog.format_type(t.oid, NULL) AS "Name",
pg_catalog.obj_description(t.oid, 'pg_type') AS "Description"
FROM pg_catalog.pg_type t
LEFT JOIN pg_catalog.pg_namespace n ON n.oid = t.typnamespace
WHERE (t.typrelid = 0
OR
(SELECT c.relkind = 'c'
FROM pg_catalog.pg_class c
WHERE c.oid = t.typrelid))
AND NOT EXISTS
(SELECT 1
FROM pg_catalog.pg_type el
WHERE el.oid = t.typelem
AND el.typarray = t.oid)
AND n.nspname <> 'pg_catalog'
AND n.nspname <> 'information_schema'
AND n.nspname ~ (:schema_name)
AND pg_catalog.pg_type_is_visible(t.oid)
AND t.typowner::regrole::text ~ quote_ident(:old_role_name))s;
/****************************************************************************************
* Get all VIEW owned by `old_role_name` and change owner to `new_role_name`
****************************************************************************************/
SELECT ChangeObjectsOwnerShip(
'ALTER VIEW ' || quote_ident("Name") || ' OWNER TO ' || quote_ident(:new_role_name))
FROM
(SELECT n.nspname AS "Schema",
c.relname AS "Name",
CASE c.relkind
WHEN 'r' THEN 'table'
WHEN 'v' THEN 'view'
WHEN 'm' THEN 'materialized view'
WHEN 'i' THEN 'index'
WHEN 'S' THEN 'sequence'
WHEN 's' THEN 'special'
WHEN 'f' THEN 'foreign table'
WHEN 'p' THEN 'partitioned table'
WHEN 'I' THEN 'partitioned index'
END AS "Type",
pg_catalog.pg_get_userbyid(c.relowner) AS "Owner"
FROM pg_catalog.pg_class c
LEFT JOIN pg_catalog.pg_namespace n ON n.oid = c.relnamespace
WHERE c.relkind IN ('v','')
AND n.nspname <> 'pg_catalog'
AND n.nspname <> 'information_schema'
AND n.nspname !~ '^pg_toast'
AND n.nspname ~ (:schema_name)
AND pg_catalog.pg_table_is_visible(c.oid)
AND pg_catalog.pg_get_userbyid(c.relowner) ~ quote_ident(:old_role_name))s;
/********************************************
* Delete created function
********************************************/
DROP FUNCTION ChangeObjectsOwnerShip ;
This is all great, but how do apps and users actually access the database?
Enter HashiCorp Vault.
Vault is a fantastic cloud native service for all your secret storage & cryptography needs. But I won’t go into a detailed presentation of what it can do for you, I’ll focus on the features my team and I used to solve the problem at hand.
Credentials for apps
Every application pod that starts needs to access its database to be operational. Generally speaking, these credentials can be set somewhere in a config file, or delivered dynamically to the app.
Vault provides a plethora of interfaces for dynamic secret distribution. We chose to use the Vault Agent Sidecar Injector. The Vault injector is a K8S controller than runs inside the cluster and intercepts pod startup events. When the pod has the right annotations, the controller injects an init container that fetches credentials from Vault and mounts them to a file inside the pod before exiting. The init container can fetch any kind of secret from Vault.
Since our goal is to have app credentials rotated often, we decided to go with Vault’s PostgreSQL DB secrets engine for its ability to generate dynamic credentials. Whenever a call is made to the DB engine (by the init container for example), it runs a set of predefined SQL statements on the database to create a temporary role. The role is temporary because the DB engine can be configured to destroy it after a specific amount of time.

All this happens in a few seconds, adding very little latency to the pod startup process.
Credentials for humans
The DB Engine we mentioned previously is configured to manage temporary credentials for apps (app role) and humans too (human_ro & human_rw roles).
Engineers won’t be using an init container to fetch their credentials though, a simple API call is enough.
Assuming they’ve been given the required permission, the easiest way for an engineer to generate temporary credentials, is to use the Vault CLI.
|
|
And that’s it really. If they’re in the right network zone, they can directly connect to the DB using these credentials.
Since Vault logs all calls in its audit log, it is very easy to monitor who accessed the DBs and what role they used.
👉 How do you ensure your app has reliable access to the DB regardless of password rotation?
In our system, as a pod starts, it fetches a set of temporary credentials provided by the Vault DB Engine. So what happens when these credentials expire?
It depends on the state of the pod when the credentials do expire. If the pod is dead, nothing happens. Other pods have replaced it and have their own credentials. If the pod is still running, unexpected behaviours might occur.
To avoid having people losing their sanity trying to debug an obscure issue caused by a dropped DB connection, we decided to find a way to have the pods die before their credentials expire.
We could have the apps exit after a set amount of time. The pod would die, and the Kubernetes scheduler would start another one with a new set of credentials. This would work fine, but it would mean we’d need our developer colleagues to introduce a change to their microservices. Following this path entirely contradicts the principle of loose coupling, and introduces friction that should not exist in an organisation that produces & runs microservices.
So the pods should be killed by an external entity before their credentials expire. Target’s pod-reaper can kill pods whenever they reach a certain age. I installed it, configured it to target specific pods, and set the right annotations on those pods to allow them to be “reaped”. I also configured pod-reaper to check if the deployment had enough healthy pods before killing a target.
My team settled on having the pods reaped every 24 hours, and the credentials expire after 72 hours. These timespans meant the team wouldn’t have to worry about service disruptions at night or during the weekend.
Critique
Is root password rotation easy?
Much easier than it was.
While it’s still a manual process, having reduced it to a few actions that can be done in 5 minutes is great. It can be handed off to a junior engineer.
Does it scale?
Yes, it does.
Single pod deployments could be an issue: if pod-reaper is not configured to ensure the service’s availability, it could kill that lonely pod, causing downtime. Single pod deployments are not compatible with this system if you care about downtime. But if you need good uptime, you shouldn’t be having single pod deployments anyway.
Will the DB handle the load?
Yes, it will.
Fundamentally, PostgreSQL roles are lines in the roles table. Unless you have billions of roles, your DB should handle the temporary roles just fine. As long as you delete them properly of course.
Can Vault keep up?
In our testing, it did.
We haven’t tested it with thousands of pods though. Larger Kubernetes clusters might need to test this further.
What if Vault is not available?
If Vault went offline, new pods wouldn’t be able to start, so pod-reaper won’t reap the old ones. The service won’t be down, but won’t be able to add new pods.
That’s why monitoring is key. But if you’re using Kubernetes, you already knew that.
Our Vault instance was a high availability cluster, adding an extra bit of resilience to our setup.
Is this better for security?
Yes.
This work brings an extra layer to our security onion. Unlike us humans, machines have no issue with frequently changing passwords. So we might as well take advantage to this to reduce the likelyhood of internal leaks, and considerably hamper data exfiltration.
The big picture
Compliance people & security professionals love to talk about implementing security throughout a project’s lifetime. Reality often shows that is wishful thinking unless the people carrying out the projects are acutely aware of security issues and actively optimizing for them.
In my organisation, using a bit of Terraform, some magic from Vault’s DB Engines and pod-reaper, my team and I managed to significantly improve our databases’ security posture. This is how we managed to bake security into our product, into our infrastructure. This is effectively made possible by a decision made earlier in our organisation’s life: standardize everything.
I cannot stress this enough: for organisations looking to scale a microservice-based SaaS quickly and efficiently, standardizing components is vital to minimising technical debt and improving security.
The work described in this blog post was necessary & important for our organisation because we processed large amounts of PII. It allowed us to cover the remaining categories of security measures our DBs lacked (RBAC, logging & monitoring). Your organisation might not need all the changes I’ve described here, but I’m willing to bet your databases are not at the bleeding edge of the security automation.